
Struktura NVIDIA NeMo

Specyfikacje
- Nazwa produktu:Framework NVIDIA NeMo
- Platformy, których dotyczy problem: Windows, Linux, macOS
- Dotyczy wersji: Wszystkie wersje przed 24
- Luka w zabezpieczeniach: CVE-2025-23360
- Wynik bazowy oceny ryzyka: 7.1 (wersja CVSS 3.1)
Instrukcje użytkowania produktu
Instalacja aktualizacji zabezpieczeń:
Aby zabezpieczyć swój system, wykonaj następujące czynności:
- Pobierz najnowszą wersję ze strony NeMo-Framework-Launcher Releases w serwisie GitHub.
- Więcej informacji znajdziesz na stronie poświęconej bezpieczeństwu produktów NVIDIA.
Szczegóły aktualizacji zabezpieczeń:
Aktualizacja zabezpieczeń usuwa lukę w zabezpieczeniach środowiska NVIDIA NeMo Framework, która może prowadzić do wykonania kodu i utraty danych.amping.
Aktualizacja oprogramowania:
Jeśli używasz starszej wersji, zaleca się aktualizację do najnowszej wersji w celu rozwiązania problemu bezpieczeństwa.
Nadview
NVIDIA NeMo Framework to skalowalna i natywna dla chmury generatywna platforma sztucznej inteligencji przeznaczona dla badaczy i programistów pracujących nad Duże modele językowe, Multimodalny i Sztuczna inteligencja mowy (np Automatyczne rozpoznawanie mowy I Tekst na mowę). Umożliwia użytkownikom efektywne tworzenie, dostosowywanie i wdrażanie nowych generatywnych modeli AI poprzez wykorzystanie istniejącego kodu i wstępnie wyszkolonych punktów kontrolnych modelu.
Instrukcje konfiguracji: Zainstaluj NeMo Framework
NeMo Framework zapewnia kompleksowe wsparcie dla opracowywania modeli Large Language Models (LLM) i modeli multimodalnych (MM). Zapewnia elastyczność, aby można było go używać lokalnie, w centrum danych lub u preferowanego dostawcy chmury. Obsługuje również wykonywanie w środowiskach obsługujących SLURM lub Kubernetes.

Kuration danych
Kurator NeMo [1] to biblioteka Pythona zawierająca zestaw modułów do eksploracji danych i generowania syntetycznych danych. Są skalowalne i zoptymalizowane pod kątem procesorów graficznych, co czyni je idealnymi do selekcjonowania danych w języku naturalnym w celu trenowania lub dostrajania LLM. Dzięki NeMo Curator możesz wydajnie wyodrębniać wysokiej jakości tekst z rozległych surowych web źródła danych.
Szkolenia i personalizacja
NeMo Framework zapewnia narzędzia do efektywnego szkolenia i dostosowywania Magister prawa i modele multimodalne. Obejmuje domyślne konfiguracje dla konfiguracji klastra obliczeniowego, pobierania danych i hiperparametrów modelu, które można dostosować do trenowania na nowych zestawach danych i modelach. Oprócz wstępnego trenowania, NeMo obsługuje zarówno techniki Supervised Fine-Tuning (SFT), jak i Parameter Efficient Fine-Tuning (PEFT), takie jak LoRA, Ptuning i inne.
Dostępne są dwie opcje uruchomienia treningu w NeMo – za pomocą interfejsu API NeMo 2.0 lub za pomocą NeMo Run.
- Z NeMo Run (zalecane): NeMo Run zapewnia interfejs usprawniający konfigurację, wykonywanie i zarządzanie eksperymentami w różnych środowiskach obliczeniowych. Obejmuje to uruchamianie zadań na stacji roboczej lokalnie lub w dużych klastrach – zarówno z włączonym SLURM, jak i Kubernetes w środowisku chmurowym.
- Trening wstępny i szybki start PEFT z NeMo Run
- Korzystanie z API NeMo 2.0: Ta metoda sprawdza się dobrze w przypadku prostej konfiguracji obejmującej małe modele lub jeśli jesteś zainteresowany napisaniem własnego niestandardowego programu ładującego dane, pętli treningowych lub warstw modelu zmian. Zapewnia większą elastyczność i kontrolę nad konfiguracjami oraz ułatwia rozszerzanie i dostosowywanie konfiguracji programowo.
-
TraSzybki start z interfejsem API NeMo 2.0
-
Migracja z NeMo 1.0 do NeMo 2.0 API
-
Wyrównanie
- NeMo-Aligner [1] to skalowalny zestaw narzędzi do wydajnego dopasowywania modeli. Zestaw narzędzi obsługuje najnowocześniejsze algorytmy dopasowywania modeli, takie jak SteerLM, DPO, Reinforcement Learning from Human Feedback (RLHF) i wiele innych. Algorytmy te umożliwiają użytkownikom dopasowywanie modeli językowych, aby były bezpieczniejsze, nieszkodliwe i pomocne.
- Wszystkie punkty kontrolne NeMo-Aligner są kompatybilne z ekosystemem NeMo, co pozwala na dalszą personalizację i wdrażanie wnioskowania.
Szczegółowy przebieg pracy wszystkich trzech faz RLHF na małym modelu GPT-2B:
- Szkolenie SFT
- Szkolenie w zakresie modelu nagradzania
- Szkolenie PPO
Ponadto demonstrujemy wsparcie dla wielu innych nowatorskich metod wyrównywania:
- Inspektor ochrony danych: lekki algorytm wyrównywania w porównaniu do RLHF z prostszą funkcją straty.
- Samodzielna gra Dostrajanie precyzyjne (SPIN)
- SteerLM: technika oparta na warunkowej SFT z regulowanym wyjściem.
Aby uzyskać więcej informacji, zapoznaj się z dokumentacją: Dokumentacja wyrównania
Modele multimodalne
- NeMo Framework to zoptymalizowane oprogramowanie do szkolenia i wdrażania najnowocześniejszych modeli multimodalnych w wielu kategoriach: multimodalne modele językowe, podstawy wizji i języka, modele przekształcania tekstu na obraz i generowanie obrazów 2D przy użyciu pól radiacyjnych neuronów (NeRF).
- Każda kategoria została zaprojektowana tak, aby odpowiadać konkretnym potrzebom i postępom w danej dziedzinie, wykorzystując najnowocześniejsze modele do obsługi szerokiej gamy typów danych, w tym tekstu, obrazów i modeli 3D.
Notatka
Przenosimy obsługę modeli multimodalnych z NeMo 1.0 do NeMo 2.0. Jeśli w międzyczasie chcesz zapoznać się z tą dziedziną, zapoznaj się z dokumentacją wersji NeMo 24.07 (poprzedniej).
Wdrażanie i wnioskowanie
Platforma NeMo udostępnia różne ścieżki wnioskowania LLM, dostosowane do różnych scenariuszy wdrożenia i potrzeb w zakresie wydajności.
Wdrażanie za pomocą NVIDIA NIM
- NeMo Framework bezproblemowo integruje się z narzędziami do wdrażania modeli na poziomie przedsiębiorstwa za pośrednictwem NVIDIA NIM. Ta integracja jest obsługiwana przez NVIDIA TensorRT-LLM, zapewniając zoptymalizowane i skalowalne wnioskowanie.
- Więcej informacji na temat NIM można znaleźć na stronie NVIDIA webstrona.
Wdrażanie za pomocą TensorRT-LLM lub vLLM
- NeMo Framework oferuje skrypty i interfejsy API umożliwiające eksportowanie modeli do dwóch bibliotek zoptymalizowanych pod kątem wnioskowania, TensorRT-LLM i vLLM, a także wdrażanie wyeksportowanego modelu przy użyciu serwera wnioskowania NVIDIA Triton.
- W przypadku scenariuszy wymagających zoptymalizowanej wydajności modele NeMo mogą wykorzystywać TensorRT-LLM, specjalistyczną bibliotekę do przyspieszania i optymalizacji wnioskowania LLM na procesorach graficznych NVIDIA. Proces ten obejmuje konwersję modeli NeMo do formatu zgodnego z TensorRT-LLM przy użyciu modułu nemo.export.
- Wdrożenie LLM zakończoneview
- Wdrażanie dużych modeli językowych NeMo za pomocą NIM
- Wdrażanie dużych modeli językowych NeMo z TensorRT-LLM
- Wdrażanie dużych modeli językowych NeMo z vLLM
Obsługiwane modele
Duże modele językowe
| Duże modele językowe | Wstępne szkolenie i SFT | ZAPALENIE | Wyrównanie | Konwergencja szkoleń FP8 | TRT/TRTLLM | Konwersja do i z Przytulającej Twarzy | Ocena |
|---|---|---|---|---|---|---|---|
| Lama3 8B/70B, Lama3.1 405B | Tak | Tak | x | Tak (częściowo zweryfikowane) | Tak | Obydwa | Tak |
| Mieszanka 8x7B/8x22B | Tak | Tak | x | Tak (niezweryfikowane) | Tak | Obydwa | Tak |
| Nemotron 3 8B | Tak | x | x | Tak (niezweryfikowane) | x | Obydwa | Tak |
| Nemotron 4 340B | Tak | x | x | Tak (niezweryfikowane) | x | Obydwa | Tak |
| Baichuan2 7B | Tak | Tak | x | Tak (niezweryfikowane) | x | Obydwa | Tak |
| CzatGLM3 6B | Tak | Tak | x | Tak (niezweryfikowane) | x | Obydwa | Tak |
| Gemma 2B/7B | Tak | Tak | x | Tak (niezweryfikowane) | Tak | Obydwa | Tak |
| Gemma2 2B/9B/27B | Tak | Tak | x | Tak (niezweryfikowane) | x | Obydwa | Tak |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | Tak | Tak | x | Tak (niezweryfikowane) | x | x | Tak |
| Phi3 mini 4k | x | Tak | x | Tak (niezweryfikowane) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | Tak | Tak | x | Tak (niezweryfikowane) | Tak | Obydwa | Tak |
| StarCoder 15B | Tak | Tak | x | Tak (niezweryfikowane) | Tak | Obydwa | Tak |
| StarCoder2 3B/7B/15B | Tak | Tak | x | Tak (niezweryfikowane) | Tak | Obydwa | Tak |
| BERT110M/340M | Tak | Tak | x | Tak (niezweryfikowane) | x | Obydwa | x |
| T5 220M/3B/11B | Tak | Tak | x | x | x | x | x |
Modele języka wizji
| Modele języka wizji | Wstępne szkolenie i SFT | ZAPALENIE | Wyrównanie | Konwergencja szkoleń FP8 | TRT/TRTLLM | Konwersja do i z Przytulającej Twarzy | Ocena |
|---|---|---|---|---|---|---|---|
| NeVA (LLaVA 1.5) | Tak | Tak | x | Tak (niezweryfikowane) | x | Z | x |
| Lama 3.2 Vision 11B/90B | Tak | Tak | x | Tak (niezweryfikowane) | x | Z | x |
| LLaVA Następna (LLaVA 1.6) | Tak | Tak | x | Tak (niezweryfikowane) | x | Z | x |
Osadzanie modeli
| Osadzanie modeli językowych | Wstępne szkolenie i SFT | ZAPALENIE | Wyrównanie | Konwergencja szkoleń FP8 | TRT/TRTLLM | Konwersja do i z Przytulającej Twarzy | Ocena |
|---|---|---|---|---|---|---|---|
| SBERT 340M | Tak | x | x | Tak (niezweryfikowane) | x | Obydwa | x |
| Lama 3.2 Osadzanie 1B | Tak | x | x | Tak (niezweryfikowane) | x | Obydwa | x |
Modele Fundacji Światowej
| Modele Fundacji Światowej | Po treningu | Przyspieszone wnioskowanie |
|---|---|---|
| Kosmos-1.0-Dyfuzja-Tekst2Świat-7B | Tak | Tak |
| Kosmos-1.0-Dyfuzja-Tekst2Świat-14B | Tak | Tak |
| Cosmos-1.0-Dyfuzja-Video2World-7B | Już wkrótce | Już wkrótce |
| Cosmos-1.0-Dyfuzja-Video2World-14B | Już wkrótce | Już wkrótce |
| Cosmos-1.0-Autoregresywny-4B | Tak | Tak |
| Cosmos-1.0-Autoregresywny-Video2World-5B | Już wkrótce | Już wkrótce |
| Cosmos-1.0-Autoregresywny-12B | Tak | Tak |
| Cosmos-1.0-Autoregresywny-Video2World-13B | Już wkrótce | Już wkrótce |
Notatka
NeMo obsługuje również wstępne trenowanie zarówno dla architektur dyfuzyjnych, jak i autoregresyjnych text2world modele fundamentowe.
Sztuczna inteligencja mowy
Opracowywanie konwersacyjnych modeli AI to złożony proces, który obejmuje definiowanie, konstruowanie i trenowanie modeli w określonych domenach. Ten proces zazwyczaj wymaga kilku iteracji, aby osiągnąć wysoki poziom dokładności. Często obejmuje wiele iteracji, aby osiągnąć wysoką dokładność, dostrajanie różnych zadań i danych specyficznych dla domeny, zapewnianie wydajności szkolenia i przygotowywanie modeli do wdrożenia wnioskowania.
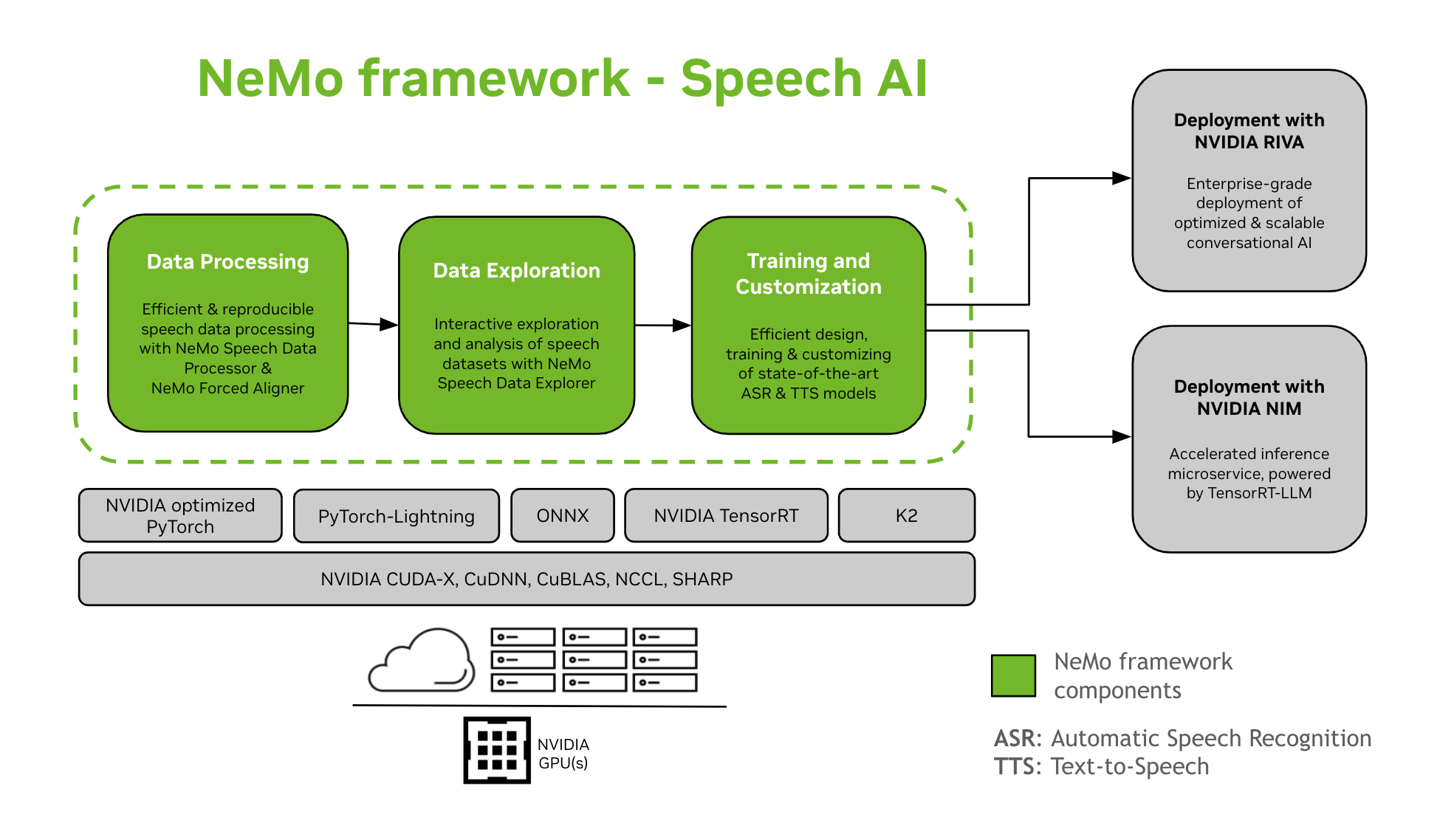
NeMo Framework zapewnia wsparcie dla szkolenia i dostosowywania modeli Speech AI. Obejmuje to zadania takie jak automatyczne rozpoznawanie mowy (ASR) i syntezę tekstu na mowę (TTS). Oferuje płynne przejście do wdrożenia produkcyjnego na poziomie przedsiębiorstwa z NVIDIA Riva. Aby pomóc programistom i badaczom, NeMo Framework obejmuje najnowocześniejsze wstępnie wyszkolone punkty kontrolne, narzędzia do przetwarzania odtwarzalnych danych mowy oraz funkcje do interaktywnej eksploracji i analizy zestawów danych mowy. Składniki NeMo Framework for Speech AI są następujące:
Szkolenia i personalizacja
NeMo Framework zawiera wszystko, co potrzebne do trenowania i dostosowywania modeli mowy (ASR, Klasyfikacja mowy, Rozpoznawanie mówcy, Diaralizacja mówcy, I TTS) w sposób możliwy do powtórzenia.
Wstępnie wytrenowane modele SOTA
- NeMo Framework zapewnia najnowocześniejsze receptury i wstępnie wyszkolone punkty kontrolne kilku ASR I TTS modeli, a także instrukcje dotyczące ich ładowania.
- Narzędzia mowy
- NeMo Framework udostępnia zestaw narzędzi przydatnych przy tworzeniu modeli ASR i TTS, w tym:
- Wymuszone nastawianie NeMo (NFA) do generowania timestów na poziomie tokenów, słów i segmentówampmowy w formie audio przy użyciu modeli automatycznego rozpoznawania mowy opartych na technologii CTC firmy NeMo.
- Procesor danych mowy (SDP), zestaw narzędzi do upraszczania przetwarzania danych mowy. Umożliwia on przedstawianie operacji przetwarzania danych w konfiguracji file, minimalizując ilość szablonowego kodu i umożliwiając powtarzalność i udostępnianie.
- Eksplorator danych mowy (SDE), oparty na Dash web aplikacja do interaktywnej eksploracji i analizy zbiorów danych mowy.
- Narzędzie do tworzenia zbiorów danych który zapewnia funkcjonalność umożliwiającą wyrównanie długiego dźwięku files z odpowiednimi transkryptami i podziel je na krótsze fragmenty, które będą odpowiednie do szkolenia modelu automatycznego rozpoznawania mowy (ASR).
- Narzędzie porównawcze dla modeli ASR w celu porównania przewidywań różnych modeli ASR dotyczących dokładności słów i poziomu wypowiedzi.
- Ewaluator ASR do oceny wydajności modeli ASR i innych funkcji, takich jak wykrywanie aktywności głosowej.
- Narzędzie do normalizacji tekstu do zamiany tekstu pisanego na mówiony i odwrotnie (np. „31st” vs. „thirty first”).
- Ścieżka do wdrożenia
- Modele NeMo, które zostały wytrenowane lub dostosowane przy użyciu NeMo Framework, można zoptymalizować i wdrożyć za pomocą NVIDIA Riva. Riva udostępnia kontenery i wykresy Helm zaprojektowane specjalnie w celu automatyzacji kroków wdrażania za pomocą przycisku.
Inne zasoby
- NeMo:Główne repozytorium dla NeMo Framework
- NeMo–Uruchomić:Narzędzie do konfigurowania, uruchamiania i zarządzania eksperymentami uczenia maszynowego.
- NeMo-Aligner: Skalowalny zestaw narzędzi do efektywnego dopasowywania modeli
- NeMo-Kurator: Skalowalny zestaw narzędzi do wstępnego przetwarzania i gromadzenia danych dla LLM
Dołącz do społeczności NeMo, zadawaj pytania, uzyskaj wsparcie lub zgłaszaj błędy.
- Dyskusje o NeMo
- Problemy NeMo
Języki programowania i frameworki
- Pyton:Główny interfejs do korzystania z NeMo Framework
- palnik:Framework NeMo jest zbudowany na bazie PyTorch
Licencje
- Repozytorium NeMo Github jest licencjonowane na podstawie licencji Apache 2.0
- NeMo Framework jest licencjonowany na podstawie NVIDIA AI PRODUCT AGREEMENT. Pobierając i używając kontenera, akceptujesz warunki i postanowienia tej licencji.
- Kontener NeMo Framework zawiera materiały dotyczące lamy, które podlegają Umowie licencyjnej społeczności Meta Llama3.
Przypisy
Obecnie trwają prace nad obsługą modeli multimodalnych przez NeMo Curator i NeMo Aligner, które będą wkrótce dostępne.
Często zadawane pytania
P: Jak mogę sprawdzić, czy mój system jest zagrożony luką?
A: Możesz sprawdzić, czy Twój system jest zagrożony, weryfikując zainstalowaną wersję NVIDIA NeMo Framework. Jeśli jest ona niższa niż wersja 24, Twój system może być podatny.
P: Kto zgłosił problem bezpieczeństwa CVE-2025-23360?
A: Problem bezpieczeństwa został zgłoszony przez Or Peles – JFrog Security. NVIDIA potwierdza swój wkład.
P: W jaki sposób mogę otrzymywać powiadomienia o przyszłych biuletynach bezpieczeństwa?
A: Odwiedź stronę poświęconą bezpieczeństwu produktów NVIDIA, aby zasubskrybować powiadomienia o biuletynach bezpieczeństwa i być na bieżąco z aktualizacjami zabezpieczeń produktów.
Dokumenty / Zasoby
 | Struktura NeMo |
Odniesienia
- Instrukcja obsługimanual.tools